HTTP 是基于 TCP/IP 的关于数据如何在万维网中如何通信的协议
HTTP 报文的组成部分
- 请求报文:请求行、请求头、空行、请求体
- 响应报文:状态行、响应头、空行、响应体
HTTP 方法
GET、POST、HEAD、PUT、DELETE、CONNECT、OPTIONS、TRACE
**HTTP 特点:**简单快速,灵活,无连接,无状态
一、Get 和 Post 的区别?
- GET 在浏览器回退时是无害的,而 POST 会再次提交请求
- GET 产生的 URL 地址可以被收藏,而 POST 不可以
- GET 请求会被浏览器主动缓存,而 POST 不会,除非手动设置
- GET 请求只能进行 url 编码,而 POST 支持多种编码方式
- GET 请求参数会被完整保留在浏览器历史记录里,而 POST 中的参数不会保留
- GET 请求在 URL 中传送的参数是有长度限制的,而 POST 是没有限制的 注意:HTTP 协议 未规定 GET 和 POST 的长度限制;GET 的最大长度显示是因为 浏览器和 web 服务器限制了 URI 的长度。不同的浏览器和 WEB 服务器,限制的最大长度不一样,要支持 IE,则最大长度为 2083byte,若只支持 Chrome,则最大长度 8182byte
- 对参数的数据类型,GET 只接受 ASCII 字符,而 POST 没有限制
- GET 比 POST 更不安全,因为参数直接暴露在 URL 中,所以不是用来传递敏感信息的
- GET 参数通过 URL 传递的,POST 放在 Request body 中
- GET 和 POST 本质上就是 TCP 链接, GET 产生一个 TCP 数据包;POST 产生两个 TCP 数据包,注意:并不是所有浏览器都会在 POST 中发送两次包,Firefox 就只发送一次
- 对于 GET 方式的请求,浏览器会把 http header 和 data 一并发送出去,服务器响应 200(返回数据)
- 对于 POST,浏览器先发送 header,服务器响应 100 continue,浏览器再发送 data,服务器响应 200 ok(返回数据)
二、HTTP 常见状态码
- 1xx:指示信息,表示请求已接收,继续处理
- 2xx:成功,表示请求已被成功接收
- 3xx:重定向,要完成请求必须进行更进一步的操作
- xx:客户端错误,请求有语法错误或请求无法实现
- 5xx:服务器错误,服务器未能实现合法的请求
特殊状态码
- 206 Partial Content: 客户发送了一个带有 Range 头的 GET 请求,服务器完成了它
- 301 Moved Permanently: 所请求的页面已经转移至新的 url -> "永久重定向"
- 302 Found: 所有请求的页面已经临时转移至新的 url -> "临时重定向"
- 304 Not Modified:客户端有缓冲的文档并发出了一个条件性的请求 服务器告诉客户,原来缓冲的文档还可以继续使用
- 400 客户端请求有语法错误,不能被服务器所理解
- 401 请求未经授权,这个状态码必须和 www-Authenticate 报头域一起使用
- 403 对被请求页面的访问被禁止 -> forbidden
- 505 服务器发送不可预期的错误,原来缓冲的文档还可以继续使用
- 503 请求未完成,服务器临时过载或宕机,一段时间后可能恢复正常
三、什么是持久连接和管线化
持久连接 (HTTP1.1 版本 1.0 不支持)
HTTP 协议采用“请求-应答”模式,当使用普通模式,即非 keep-alive 模式时,每个请求/应答 客户和服务器都要新键一个连接,完成之后立即断开连接(HTTP 协议为无连接的协议);当使用 keep-alive 模式(又称为持久连接,连接重用)时,keep-alive 功能使客户端到服务器端的连接有效,当出现对服务器的后继请求时,keep-alive 功能避免了建立或重新建立连接
管线化
四、说说 HTTP、HTTPS、HTTP2、HTTP3
为什么 HTTPS 比 HTTP 安全?
五、TCP 的三次握手和四次挥手
六、网络模型
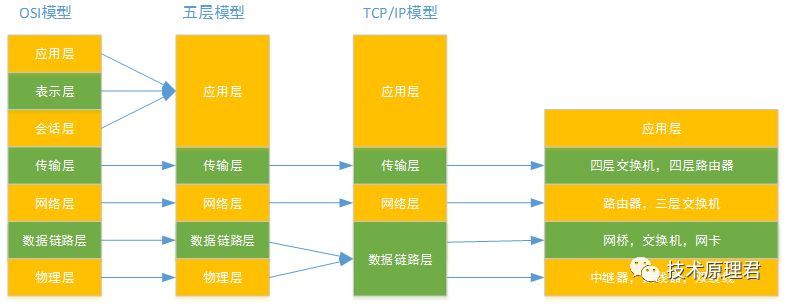
OSI(Open System Interconnection,开放系统互连) 七层模型
建立七层模型的主要目的是为解决异种网络互连时所遇到的兼容性问题,其最主要的功能使就是帮助不同类型的主机实现数据传输。它的最大优点是将服务、接口和协议这三个概念明确地区分开来,通过七个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯.
- 物理层
- 数据链路层
- 网络层
- 传输层
- 会话层
- 表示层
- 应用层
TCP/IP 四层模型
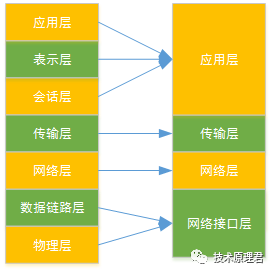
五层模型
五层体系结构包括:应用层、运输层、网络层、数据链路层和物理层。五层协议只是 OSI 和 TCP/IP 的综合,实际应用还是 TCP/IP 的四层结构。
七、浏览器(HTTP)缓存
浏览器缓存有两种:
强制缓存
协商缓存
强制缓存
http1.0 -> Expires, 是响应头里面的一个字段表示的是文件过期时间。是一个绝对时间
缺点:服务器的时区和浏览器时区不一致的时候就会导致缓存失效
HTTP1.1 -> Cache-Control, 是相对时间
Cache-Control 的可选值:
max-age: 缓存过期时间,是一个相对时间 public: 表示客户端和代理服务器都会缓存 private: 表示只在客户端缓存 no-cache: 协商缓存标识符,表示文件会被缓存但是需要和服务器协商 no-store: 表示文件不会被缓存
协商缓存
HTTP1.0 -> Last-Modified/if-Modified-Since, 时间粒度是秒
缺点:
- 文件有可能在 1s 内修改内容
- 文件内容修改后又复原
缓存的地方
- form memory cache
- from dist cache
问题:何时缓存在内存,合适缓存在硬盘呢?
- 大一点的文件会缓存在 dist 里面,因为内存也是有限的,磁盘的空间更大
- 小一点文件 js,图片存的是 memory
- css 文件一般存在 dist
- 特殊情况 memory 大小是有限制的,浏览器也会根据自己的内置算法,把一部分 js 文件存到 dist 里面